Parallelism#
Principle#
The NNGT package provides the possibility to use multithreaded algorithms to generate networks. This feature means that the computation is distributed on several CPUs and can be useful for:
machines with several cores but low frequency
generation functions requiring large amounts of computation
very large graphs
However, the multithreading part concerns only the generation of the edges; if
a graph library such as graph-tool, igraph, or networkx is used,
the building process of the graph object will be taken care of by this library.
Since this process is not multithreaded, obtaining the graph object can be much
longer than the actual generation process.
NNGT provides two types of parallelism:
shared-memory parallelism, using OpenMP, which can be set using
nngt.set_config()("multithreading", True)or, setting the number of threads, withnngt.set_config("omp", 8)to use 8 threads.distributed-memory parallelism using MPI, which is set through
nngt.set_config("mpi", True). In that case, the python script must be run asmpirun -n 8 python name_of_the_script.pyto be run in parallel.
These two ways of running code in parallel differ widely, both regarding the situations in which they can be useful, and in the way the user should interact with the resulting graph.
The easiest tool, because it does not significantly differ from the single-thread case on the user side, is OpenMP, which is why we will describe it first. Using MPI is a lot different and will require the user to adapt the code to use it and will depend on the backend used.
Parallelism and random numbers#
When using parallel algorithms, additional care is necessary when dealing with random number generation. Here again, the situation differs between the OpenMP and MPI cases.
Warning
Never use the standard random module, only use numpy.random!
When using OpenMP, the parallel algorithms will use the random seeds defined
by the user through nngt.set_config("seeds", list_of_seeds). One seed per
thread is necessary.
These seeds are not used on the python level, so they are independent from
whatever random generation could happen using numpy
(e.g. to set node positions in space, or to generate attributes).
To make a simulation fully reproducible, the user must set both the random
seeds and the python level random number generators through the master seed.
For instance, with 4 threads:
master_seed = 0
nngt.set_config({"msd": master_seed, "seeds": [1, 2, 3, 4]})
Note
If the seeds are not provided, then they are generated automatically,
from the master seed for the first call to a graph-generation method
(using 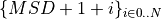 , with N the number of
threads), then using a random number generated through numpy. This means
that all previous calls to
, with N the number of
threads), then using a random number generated through numpy. This means
that all previous calls to numpy.random will affect the
random seeds used for the second or later calls to graph-generation
methods unless new seeds are manually set by the user befor each new
call (this does not mean that the code will not be reproducible, only
that changes in the random calls in the code that occur before calls to
graph-generation methods would affect the random structure of the
generated graphs).
Warning
This is also how you should initialize random numbers when using MPI!
This may surprise experienced MPI users, but NNGT is implemented in such a way that shared properties are generated on all threads through the initial python master seed, then generation algorithms save the current common state, then re-initialize the RNGs for parallel generation, and finally restore the previous, common random state once the parallel generation is done. Of course the parallel initialization differs every time, but it is changed in a reproducible way through the master seed.
Using MPI (distributed-memory parallelism)#
Note
MPI algorithms are currently restricted to
gaussian_degree() and
distance_rule() only.
Handling MPI can be significantly more difficult than using OpenMP because it differs more strongly from the “standard” single-thread case.
NNGT provides two different ways of using MPI:
When using one of the three graph libraries (graph-tool, igraph, or networkx), the connections are generated in parallel, but the final object is stored only on the master process. This means that in this case, the memory load will weigh only on this process, leading to a strong load imbalance. This feature is aimed at people who would require parallelism to speed up their graph generation but, for some reason, cannot use the OpenMP parallelism.
For “real” memory distribution, e.g. for people working on clusters, who require a balanced memory-load, NNGT provides a custom backend, that can be set using
nngt.set_config('backend', 'nngt'). In this case, each process stores only a fraction of all the edges. However, nodes and graph properties are fully available on all processes.
Warning
When using MPI with graph-tool, igraph, or networkx, all operations on the
graph that has been generated must be limited to the root process. To that
end, NNGT provides the on_master_process() function that
returns True only on the root MPI process.
Using the ‘nngt’ backend, the edge_nb() method, as well
as all other edge-related methods will return information on the local
edges only!
Fully distributed setup#
The python file should include (before any graph generation):
import nngt
msd = 0 # choose a master seed
seeds = [1, 2, 3, 4] # choose initial seeds, one per MPI process
nngt.set_config({
"mpi": True,
"backend": "nngt",
"msd": msd,
"seeds": seeds,
})
The file should then be executed using:
>>> mpirun -n 4 python name_of_the_script.py
Note
Graph saving is available in parallel in the fully distributed setup
through the to_file() and save_to_file()
functions as in any other configuration.
Parallelized generation algorithms#
Generation of some directed graphs are available with parallel implementations (see table below). No undirected graph generation mechanisms are currently implemented.
Function |
OMP |
MPI |
|---|---|---|
no |
no |
|
no |
no |
|
yes |
yes |
|
no |
no |
|
yes |
yes |
|
yes |
yes |
|
yes |
yes |
|
no |
no |
|
no |
no |
Go to other tutorials: